Allgemeine Informationen
| Information | |
|---|---|
| Informationen | |
| Betriebssystem | Alle |
| Service | KI |
| Interessant für | Studierende und Angestellte |
| HilfeWiki des ZIM der Uni Paderborn | |
KI-Sprachmodelle sind ein wesentlicher Bestandteil moderner künstlicher Intelligenz und finden Anwendung in verschiedensten Bereichen, von der automatisierten Textverarbeitung bis hin zu interaktiven Dialogsystemen. Diese Modelle sind darauf trainiert, menschliche Sprache zu verstehen und zu verarbeiten, und ermöglichen es Maschinen, menschenähnliche Texte zu generieren und zu analysieren.
Open-Source-Sprachmodelle[Bearbeiten | Quelltext bearbeiten]
Open-Source-Sprachmodelle bieten eine breite Palette von Stärken, die für unterschiedliche Anwendungen optimiert sind. Hier sind einige Beispiele für solche Modelle und ihre spezifischen Vorteile:
- Metas Llama 3.1 8B Instruct: Dieses entwickelte Modell ist bekannt für seine hohe Geschwindigkeit und allgemeine Leistungsfähigkeit. Es eignet sich hervorragend für Anwendungen, die schnelle und präzise Antworten erfordern.
- DeepSeek R1: Besonders stark im Bereich des Reasonings und der Problemlösung. Dieses Modell aus China kann komplexe logische Schlussfolgerungen ziehen und zeigt eine hohe Performance in anspruchsvollen kognitiven Aufgaben, allerdings mit einer Tendenz zu politischem Bias.
- Google Gemma: Verschiede Sprachmodelle unterschiedlicher Größe für Arbeiten mit Texten, Modelle für Bildererkennungen (Vision) und Modelle zur Codegenerierung. Die Modelfamilie ist die quelloffene Alternative der Gemini-Modelle.
Die Stärke von Open-Source-Sprachmodellen liegt oft in ihrer Anpassungsfähigkeit und der Unterstützung durch eine große Community, die kontinuierlich zur Verbesserung und Weiterentwicklung dieser Modelle beiträgt.
Proprietäre Sprachmodelle[Bearbeiten | Quelltext bearbeiten]
Neben den öffentlich zur Verfügung stehenden Sprachmodellen, gibt es proprietäre Sprachmodelle wie OpenAIs GPT- oder Omni-Modelfamilie. Diese werden von Unternehmen kommerziell betrieben oder mit Lizenzen kontrolliert. Ein lokales Angebot ist daher meist nicht umsetzbar. Einige bekannte Unternehmen und deren KI-Modelle sind:
- OpenAI: GPT und Omni Modelle (https://platform.openai.com/docs/models)
- Mistral AI: Medium und Large Mistral Modelle ( https://docs.mistral.ai/getting-started/models/models_overview/ )
- xAI: Grok ( https://docs.x.ai/docs/models )
- Anthropic: Claude ( https://docs.anthropic.com/en/docs/about-claude/models/overview )
- Google: Gemini ( https://ai.google.dev/gemini-api/docs/models?hl=de )
Es gibt allerdings auch Modelle dieser Provider die Open-Source gestellt wurden. So ist Mistrals Small- und Research-Modelle oder OpenAIs Whisper-Model zu erwähnen.
Welche Sprachmodelle stehen mir an der Universität zur Verfügung?[Bearbeiten | Quelltext bearbeiten]
Unser Angebot umfasst eine Vielzahl an Open-Source-Modellen, die von der GWDG/KISSKI betrieben werden. Zusätzlich bieten wir Zugang zu den bekannten KI-Modelle von OpenAI. Die Auswahl wird stetig um neu veröffentliche Modelle erweitert und veraltete Modelle werden entfernt. Sie können die Modelle über die Chat-Oberfläche https://ai-chat.upb.de nutzen (Hinweise zur Chat-Anwendung) oder mittels eines API-Keys über das Gateway der Universität.
Allrounder / Große Sprachmodelle (LLMs)[Bearbeiten | Quelltext bearbeiten]
Im Vergleich zu spezialisierten Modellen für Aufgaben wie Bilderkennung, Programmiersprachen, Schlussfolgerungen oder (Fremd-)Sprachen sind die Modelle in der Kategorie "Allrounder" für all diese Aufgaben ein gutes Mittel. Die meisten Allrounder sind auf ausreichenden Trainingsdaten für verschiedene Sprachen trainiert. Wenn allerdings z.B. vertieftes Wissen und umfangreicher Wortschatz einer Sprache benötigt wird, schneiden die Allrounder oft schlechter ab als ein Modell welches auf einen größeren Korpus für die ausgewählte Sprache oder Aufgabe trainiert wurde. Die folgende Liste der Allrounder-Sprachmodelle ist nach dem Datum der Veröffentlichung sortiert:
| GPT-5
OpenAIs aktuelles GPT-Modell ist GPT-5 und vereint eine Serie von Modellen. Anfragen werden intern an ein Mini-, Nano-, Large- oder Reasoning-Modell versendet. Dieses Vorgehen soll die Entscheidung und Komplexität für Nutzende entlasten. In der Vergangenheit führte die fehlende Transparenz und Steuerung aber auch zu Kritik an der Qualität der Dialoge, da nun nicht immer das große Sprachmodell verwendet wurde. Weiterhin sind auch ältere Modelle der GPT-4.1 und GPT-4o Serie verfügbar.
Veröffentlicht: August 2025 Unterstützte Sprachen: Multilingual mit "mehr als 80 Sprachen, darunter Englisch, Spanisch, Französisch, Deutsch, Chinesisch, Japanisch, Arabisch und viele mehr." Wissensstand: September 2024
|
Qwen 3 (Non-Reasoning)
Das Qwen 3 Modell ist eigentlich ein Reasoning-Model, verfügt allerdings über eine "Non-Reasoning" Anweisung. Die zugrunde liegende Architektur des Models ändert sich dabei nicht, aber ermöglicht es das Model anzuweisen ohne "Thinking"-Iterationen zu arbeiten und stattdessen direkt eine Antwort zu generieren. Das erlaubt es Nutzende möglichst schnell Texte zu generieren und das Model auch für einfache Aufgaben ohne benötigte Schlussfolgerungen zu nutzen.
Veröffentlicht: April 2025 Unterstützte Sprachen: Multilingual mit "Unterstützung für über 119 Sprachen und Dialekte, darunter Indoeuropäisch, Sinotibetisch, Afroasiatisch, Austronesisch, Dravidisch, Turksprachen, Tai-Kadai, Uralisch, Austroasiatisch und Andere." Wissensstand: September 2024
|
| Gemma 3
Die Modell-Serie Gemma ist die Open-Source Variante der Gemini-Reihe von Google. Zu betonen ist dass das Open-Source-Modell von der GWDG/KISSKI betrieben wird und damit kein Datenfluss zu Google besteht. Im Vergleich dazu, können die Gemini-Modelle, welche nicht Open-Source sind, leider nicht von der GWDG/KISSKI betrieben werden.
Veröffentlicht: März 2025 Unterstützte Sprachen: Multilingual. "Unterstützung für über 140 Sprachen" * Wissensstand: August 2024
|
Qwen 2.5
Die open-source Qwen-Modellserie wird von Alibaba Cloud entwickelt. Neben den LLM-Varianten gibt es weitere Experten-Modelle als Coding- und Math-Modell (Qwen-Coder und Qwen-Math), sowie multimodale Modelle (Qwen-VL und Qwen-Audio).
Veröffentlicht: September 2024 Unterstützte Sprachen: Multilingual mit "Unterstützung für über 29 Sprachen, darunter Chinesisch, Englisch, Französisch, Spanisch, Portugiesisch, Deutsch, Italienisch, Russisch, Japanisch, Koreanisch, Vietnamesisch, Thailändisch, Arabisch und weitere." Wissensstand: September 2024
|
| Llama 3.3
Meta - der Mutterkonzern hinter Facebook und Instagram - entwickelt die bekannten Open-Source Llama Modelle. Neuere Modelle wie das Llama 4 Model sind leider unter einer Lizenz veröffentlicht worden, welche es nicht erlaubt diese in der EU zu betreiben. Meta stellt sich damit gegen die Entwicklungen innerhalb der EU und Regulierungen. Das Angebot der Hochschule ist daher auf das ältere Model Llama 3.3 begrenzt.
Veröffentlicht: Dezember 2024 Unterstützte Sprachen: Englisch, Deutsch, Französisch, Italienisch, Portugiesisch, Hindi, Spanisch und Thailändisch. Wissensstand: Dezember 2023 |
Mistral Large 2
Das französische Unternehmen "Mistral" wird in den Medien oft als die europäische Lösung betitelt, welche mit den großen Sprachmodellen der amerikanischen Konkurrenten mithalten kann. Durch den Unternehmenssitz innerhalb der EU, ist es im Vergleich zu anderen Anbietern in den USA, regulierter. Folglich sind Angaben zu Trainings-Daten und der Umgang mit Lizenzen freundlicher gegenüber EU-Verordnungen und -Richtlinien. Hier muss allerdings unterschieden werden, dass es nur um die Entwicklung der Modelle und damit um Fragen geht, wie die Transparenz der Traningsdaten. Betrieben werden aber alle Modelle im Angebot mit der Kennzeichnung "GWDG" im KISSKI-Rechenzentrum. Im Vergleich zur Nutzung von Produkten wie ChatGPT, fließen bei der Nutzung des AI-Chats und den GWDG-Modellen also keine Daten in die USA.
Veröffentlicht: Juli 2024 Unterstützte Sprachen: Französisch, Deutsch, Spanisch, Italienisch, Niederländisch, Portugiesisch, Russisch, Koreanisch, Japanisch, Chinesisch. Wissensstand: Juli 2024
|
Schlussfolgernde Sprachmodelle / Reasoning-Models (LRMs)[Bearbeiten | Quelltext bearbeiten]
Reasoning oder Schlussfolgerungsfähigkeit ist ein entscheidender Aspekt moderner KI-Sprachmodelle. Diese Fähigkeit erlaubt es Sprachmodellen, ausgiebige logische Zusammenhänge zu erkennen und komplexe kontextbezogene Schlussfolgerungen zu ziehen. Modelle wie DeepSeek R1 und GPT o4-mini sind z.B. dafür bekannt, fortschrittliche Reasoning-Qualitäten zu besitzen, die sie in Anwendungen wie juristische Analysen oder interaktive Lernsysteme besonders nützlich machen.
| Qwen 3
Veröffentlicht: April 2025 Unterstützte Sprachen: Multilingual mit "Unterstützung für über 119 Sprachen und Dialekte, darunter Indoeuropäisch, Sinotibetisch, Afroasiatisch, Austronesisch, Dravidisch, Turksprachen, Tai-Kadai, Uralisch, Austroasiatisch und Andere." Wissensstand: September 2024
Veröffentlicht: April 2025 Unterstützte Sprachen: Multilingual mit "Unterstützung für über 119 Sprachen und Dialekte, darunter Indoeuropäisch, Sinotibetisch, Afroasiatisch, Austronesisch, Dravidisch, Turksprachen, Tai-Kadai, Uralisch, Austroasiatisch und Andere." Wissensstand: April 2025
|
Qwen QwQ
Veröffentlicht: März 2025 Unterstützte Sprachen: Multilingual mit "Unterstützung für über 119 Sprachen und Dialekte, darunter Indoeuropäisch, Sinotibetisch, Afroasiatisch, Austronesisch, Dravidisch, Turksprachen, Tai-Kadai, Uralisch, Austroasiatisch und Andere." Wissensstand: September 2024
|
| DeepSeek R1
Das Reasoning-Model DeepSeek vom gleichnamigen chinesischen Unternehmen, hatte zur Veröffentlichung Wellen in den Medien geschlagen. Grund war der Vorwurf von politischem Bias und Zensur. Das Modell R1 wurde mittlerweile auf die Version R1-0528 aktualisiert und vergleicht sich mit Modellen wie Qwen3, OpenAIs o3 und Googles Gemini 2.5 Pro.
Veröffentlicht: Dezember 2024 Unterstützte Sprachen: Englisch, ... Wissensstand: Dezember 2023
Diese Distill-Modellvariante setzt als Basis-Model Metas Llama 3.3 70B ein und wurde durch das Model DeepSeek R1 weiter trainiert.
Veröffentlicht: Dezember 2024 Wissensstand: Dezember 2023
|
GPT OSS
Veröffentlicht: August 2025 Wissensstand: Juni 2024
|
| o4 | o3 |
Bilderkennung / Vision-Models[Bearbeiten | Quelltext bearbeiten]
Neben bildgenerierenden Modellen in Form von Text-zu-Bild oder Bild-zu-Bild, gibt es auch den Anwendungsfall Bild-zu-Text. KI-Modelle mit der sog. Vision-Fähigkeit sind in der Lage Bilder (+ Instruktionen) als Eingabe zu verarbeiten und Fragen oder Aufgaben in Text-Form zu beantworten. Diese Modelle können z.B. zum Generieren von Bildbeschreibungen genutzt werden, Analysen des Bildes welche für den Nutzenden ohne Hintergrundwissen nicht beantwortet werden können, Kategorisierung/Labeling von Bildern, extrahieren von sichtbaren Informationen aus dem Bild, und vieles mehr.
| Qwen 2.5 VL | InternVL 2.5 |
| Gemma 3 | GPT-4.1 mini |
Programmierung / Coding[Bearbeiten | Quelltext bearbeiten]
Auch Programmiersprachen lassen sich trainieren und damit als Unterstützung in der Software-Entwicklung nutzen. Vor allem im Bereichen der Code-Generierung, Code-Reasoning, Fehlerbehebung und Coding-Agenten.
| Codestral
Das Model wurde von Mistral entwickelt und für über 80 Programmiersprachen spezialisiert, wie Python, Java, C, C++, JavaScript und Bash.
Veröffentlicht: Dezember 2024 Wissensstand: Ende 2021
|
Qwen 2.5 Coder
Das Model wurde von Alibaba Cloud entwickelt und für über 40 Programmiersprachen spezialisiert, wie Coffee, Groovy, Swift, Json, C#, Kotlin, Rust, Java, VB, Haskell, R, Shell, Julia, PHP, Scheme, F#, Python, JS, Ruby, Scala, AWK, C, C++, Go, Lua, Racket, TS, Clisp, Elixir, Fortran, Perl, Elisp, Pascal, Tcl, VimL, Erlang, Dart und HTML.
Version: Qwen 2.5 Coder 32B Veröffentlicht: November 2024 Wissensstand: September 2024
Quelle: huggingface.co/qwen, qwenlm.github.io |
Aufgabenmodelle / Task-Models[Bearbeiten | Quelltext bearbeiten]
Kleine Aufgaben wie z.B. einen Titel für einen Chat zu generieren, werden oft von den kleinen Varianten der großen Sprachmodelle übernommen. Diese sind für die Aufgabe völlig ausreichend und verbrauchen weniger Ressourcen. Damit sind sie oft auch günstiger und schneller als die Verwendung der großen Sprachmodelle. Wie groß Sprachmodelle sind, kann anhand von Bezeichnern wie "mini" und "nano" oder der "Billion-Parameter" im Modelnamen eingeschätzt werden. Beispiele sind "Llama 3.1 8B" gegenüber "Llama 3.1 70B". Diese Zahl repräsentieren die Anzahl der "Einstellungen", die ein KI-Modell während des Trainingsprozesses lernt. Jeder Parameter kann als ein kleiner Baustein betrachtet werden, welches das Modell verwendet, um bestimmte Aufgaben zu erfüllen. Ein Modell mit einer höheren Anzahl an Parametern ist oft leistungsfähiger und kann komplexere Muster erkennen. Allerdings bedeutet dies auch, dass das Modell größer ist und mehr Ressourcen benötigt, um effizient zu arbeiten. Wichtig zu beachten ist, dass mehr Parameter nicht immer gleichbedeutend mit "besser" ist. Die Qualität eines Modells hängt stark vom spezifischen Einsatzkontext ab.
| Llama 3.1 8B | GPT-4.1 mini | GPT-4o mini |
Spezialisierte Modelle[Bearbeiten | Quelltext bearbeiten]
- Vertieftes Training mit Fokus auf deutschsprachige Texten: SauerkrautLM 70B
- Vertieftes Training mit Fokus auf europäische Sprachen: Teuken 7B Research
- Medizinische Inhalte: MedGemma 27B
Welches Modell sollte ich nutzen?[Bearbeiten | Quelltext bearbeiten]
Die Wahl des passenden Sprachmodells hängt stark vom Anwendungsfall ab. Es gibt nicht das eine "beste" Modell, sondern vielmehr verschiedene Stärken und Schwächen, die je nach Bedarf unterschiedlich ins Gewicht fallen.
Allrounder oder spezialisierte Modelle?[Bearbeiten | Quelltext bearbeiten]
Allrounder sind vielseitig einsetzbar und eignen sich für Nutzer*innen, die flexibel mit vielen unterschiedlichen Aufgaben arbeiten wollen. Spezialisierte Modelle sind auf konkrete Aufgaben trainiert, etwa Programmierung, juristische Texte oder medizinische Fachsprache. Sie erzielen in diesen Nischen oft deutlich präzisere Ergebnisse, sind aber weniger universell einsetzbar. Wenn das Einsatzgebiet klar umrissen ist, kann ein spezialisiertes Modell besser passen. Für wechselnde oder schwer vorhersehbare Anforderungen sind Allrounder meist die bessere Wahl.
Ranglisten, Benchmarks und Scoring[Bearbeiten | Quelltext bearbeiten]
Im Internet finden sich zahlreiche Ranglisten und Benchmarks, in denen Modelle anhand ihrer Leistung in Tests bewertet werden. Dabei gilt es zu beachten:
- Hersteller veröffentlichen oft eigene Benchmarks, die ihre Modelle ins beste Licht rücken.
- Keine Rangliste deckt alle möglichen Anwendungsfälle ab. Ein Modell, das in akademischen Tests hervorragend abschneidet, ist nicht zwingend das nützlichste im Arbeitsalltag.
- Externe, unabhängige Vergleichsportale können einen neutraleren Überblick bieten, sind aber trotzdem nur Anhaltspunkte.
- Es gibt viele verschiedene Listen, welche je nach Metrik oder Evaluierungsmethode unterschiedliche Top-3 Modelle auswählen.
Rankings sind nützlich für eine grobe Orientierung, ersetzen aber nicht eigene Tests mit den tatsächlichen Aufgaben, die gelöst werden sollen.
Das Modell selbst befragen und vergleichen[Bearbeiten | Quelltext bearbeiten]
Eine praktische Methode, um die Stärken eines bestimmten Sprachmodells zu verstehen, besteht darin, das Modell selbst zu befragen. Viele Modelle können Hinweise geben, worin ihre spezifischen Stärken und Schwächen liegen, wodurch Nutzer*innen sie effektiver für ihre Zwecke einsetzen können.
Ein praktischer Ansatz zur Auswahl des richtigen Modells ist der direkte Vergleich:
- Dieselbe Aufgabe mit verschiedenen Modellen bearbeiten lassen.
- Die Ergebnisse systematisch prüfen: Verständlichkeit, Genauigkeit, Stil, Relevanz.
- Abwägen, welches Modell dem gewünschten Standard am nächsten kommt.
Diese Art des Praxis-Tests ist oft hilfreicher als jede externe Bewertung, da sie an Ihre individuellen Anforderungen ausgerichtet sind.
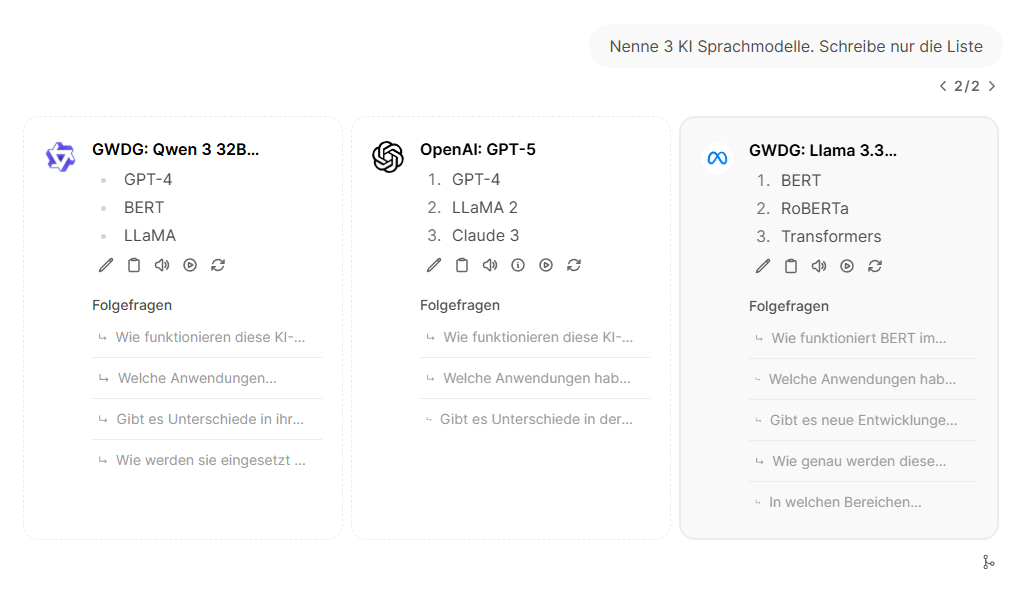
Die Chat-Oberfläche unterstützt Sie beim Vergleichen, indem Sie über das "+"-Symbol mehrere Modelle gleichzeitig auswählen können und die Antworten direkt im Vergleich sichtbar werden.
Siehe auch[Bearbeiten | Quelltext bearbeiten]
- Datenschutz bei KI-Diensten
- Der EU AI Act (KI Verordnung) und seine Bedeutung
- Halluzinationen und Validierung von Informationen bei KI
- Bias und Filter bei Künstlicher Intelligenz
- Individualisierte Einstellungsmöglichkeiten bei KI
- Hochrisiko-Anwendungen von KI im Hochschulbereich
- KI in der Lehre
- KI in der Forschung
{kind=link}
{kind=link}